Lab 4a: Self-Consistency#
This notebook introduces the Self-consistency prompting strategy, a technique that is similar to chain-of-thought prompting. However, instead of taking the obvious step-by-step, or greedy decoding, self-consistency prompts the model to sample a variety of reasoning paths. Then, the model aggregates the final answer based on multiple data points from the various paths.
Self-consistency leverages the intuition that a complex reasoning problem typically admits multiple different ways of thinking leading to its unique correct answer. According to the original paper, self-consistency improves Chain-of-thought prompting when used in a range of common arithmetic and common-sense reasoning benchmarks.
About This Lab#
Throughout this lab, you will encounter two types of interactive elements:


No coding is needed for an activity. You try to understand a concept,
answer questions, or run a code cell.
Challenges are where you test your understanding by implementing something new or taking a short quiz.
Please work through this notebook from top to bottom to avoid errors due to missing code or context.
Table of Contents#
1. Import libraries#
Let’s start by installing all required packages as specified in the requirements.txt file and importing several libraries.
!pip install --no-deps -q -r ../requirements.txt
import sys
sys.path.append('..')
import boto3
import re
import random
import numpy as np
from collections import Counter
from langchain_core.prompts import PromptTemplate
from IPython.display import Markdown, display
%load_ext autoreload
%autoreload 2
from mlu_utils.utils import *
2. Set up Bedrock for inference#
To get started, set up Bedrock and instantiate an active bedrock-runtime to query LLMs.
Let us define a custom function to run inference with Bedrock-hosted models. The code below leverages LangChain’s Bedrock integration and allows to use Bedrock-hosted models.
Next, use Bedrock for inference to test everything works as expected.
In this notebook we will use Amazon Nova Micro model, one of the models from the Amazon Nova Family. A model that offers a good balance of quality, speed, and cost. The model offers enhanced text generation capabilities, making it well-suited to language tasks with a greater degree of complexity.
# Example model prompting Nova
MODEL = "amazon.nova-micro-v1:0"
TEMP = 0.0
Markdown(generate_outputs("Hi, how are you?", MODEL, TEMP, max_tokens=128)[0])
Hello! I’m here and ready to assist you with any questions or information you need. How can I help you today?
3. Self-consistency#
Self-consistency was proposed in Self-Consistency Improves Chain of Thought Reasoning in Language Models, by Wang et al. (2022). The paper introduces a new decoding strategy to replace the naive greedy decoding used in chain-of-thought prompting. The idea is to generate multiple, diverse reasoning paths through few-shot CoT, and use those completions to verify the consistency of the model’s responses. This helps boost the performance of CoT prompting on tasks involving arithmetic and commonsense reasoning.
Below you will see an example of a Bedrock-hosted LLM improving its performance in an arithmetic task by using the self-consistency prompting technique.
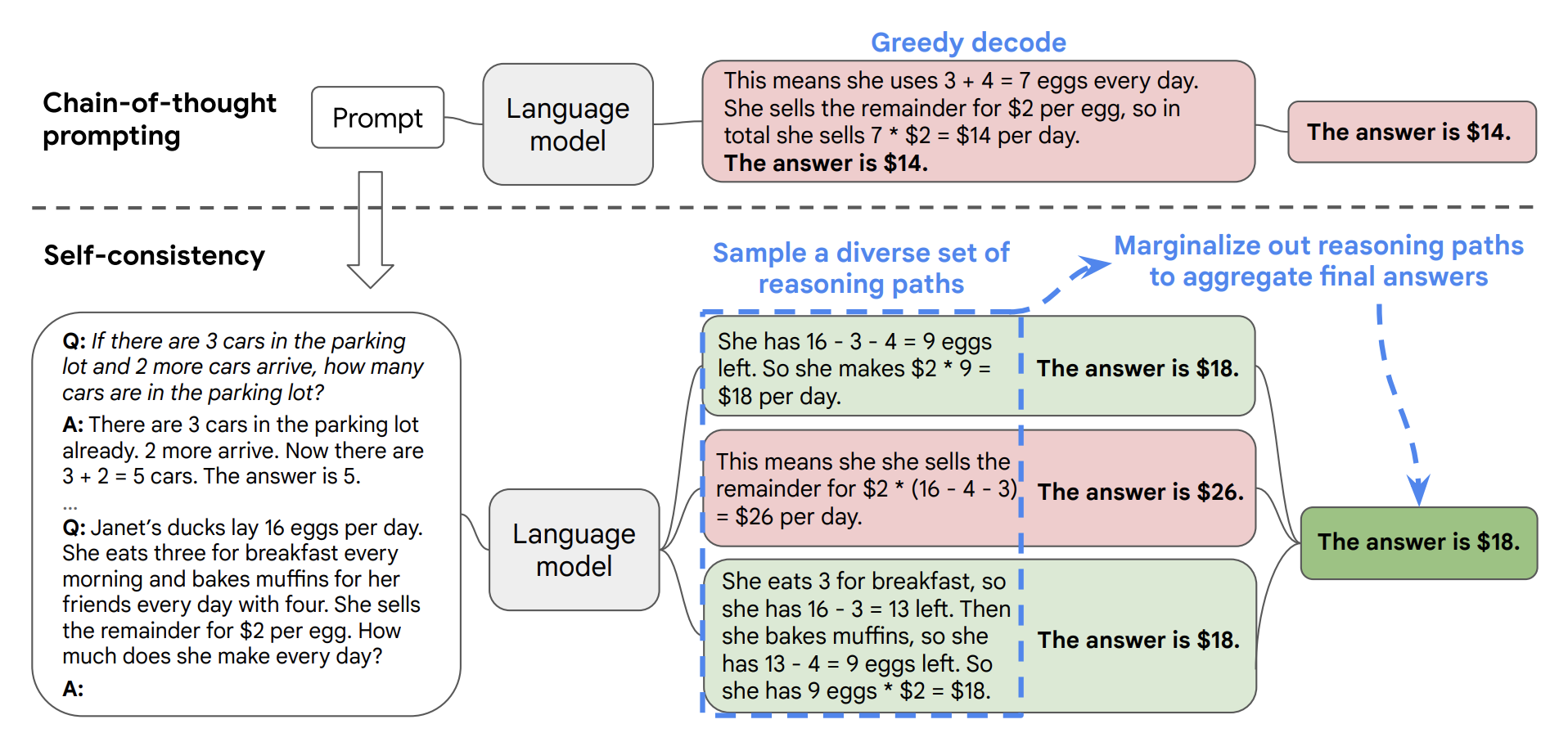
3.1 Decoding strategies for text generation#
Decoder-only, as well as encoder-decoder generative models, like Amazon Nova, generate text one token at a time, which is predicted based on the previous context. At each step, the model outputs a probability distribution, representing the likelihood of each token appearing next, given the prompt so far. Decoding is the process of turning the probability distributions generated by the model into actual text.
Greedy decoding is a deterministic decoding method that selects the token with the highest probability at each step. It is “greedy” in always choosing the individually most likely token. While simple and fast, this greediness involves the risk of getting stuck in repetitive loops, as the wider probability space is ignored. Greedy decoding can produce less creative results than sampling-based stochastic decoding methods that better capture the diversity of possible outputs.
When the temperature is set to 0 in decoder-only models, the model will always choose the word with the highest probability. Effectively, this process is equivalent to greedy decoding. This determinism means that when the same prompt is input to the model multiple times, the output generated will be always identical.
Sampling introduces stochasticity into the decoding process by randomly selecting each next word based on the probability distribution predicted by the model, rather than always picking the single most likely next token. This injects randomness: the sampled word is not guaranteed to have the highest individual probability. Sampling allows for greater diversity in the generated text and avoids the deterministic decoding’s tendency to get stuck in repetitive loops. It enables the model to better explore the full distribution of potential outputs at each time step. Sampling chooses tokens randomly in a way that better matches the model’s probabilistic predictions. The stochasticity introduced by sampling increases the model’s capacity to generate varied, creative output, showcasing a breadth of possibilities.
Read more about decoding strategies in this article: Decoding Methods and Stochasticity for Amazon Titan, Bedrock, and Beyond.
See an example of greedy decoding below, asking the same question 5 times (n=5):
prompt = """Wisdom is easily acquired when"""
TEMP = 0.0
for output in generate_outputs(prompt, MODEL, TEMP, max_tokens=128, n=5):
display(Markdown(" ".join([prompt, output])))
display(Markdown("---"))
Wisdom is easily acquired when Wisdom is often considered a deep and nuanced quality that comes from a combination of experience, reflection, and learning. While it can be acquired in various ways, it is not always easily obtained. However, there are certain contexts in which wisdom can appear more accessible:
From Teaching and Mentorship: When individuals have access to wise teachers or mentors who share their knowledge and insights, wisdom can be more readily acquired. This is because mentors can provide guidance, share personal experiences, and offer perspectives that can help others understand complex issues more deeply.
Through Reflection and Self-Examination: When people take the time to reflect on their
Wisdom is easily acquired when Wisdom is often considered a deep and nuanced quality that comes from a combination of experience, reflection, and learning. While it can be acquired in various ways, it is not always easily obtained. However, there are certain contexts in which wisdom can seem more accessible or readily available:
From Teaching and Mentorship: When individuals have access to wise teachers, mentors, or elders who have a wealth of knowledge and experience, they can more easily absorb wisdom through guidance and instruction.
Through Reflection and Self-Examination: When people take the time to reflect on their experiences, consider different perspectives, and engage in self-examination,
Wisdom is easily acquired when Wisdom is often considered a deep and nuanced quality that comes from a combination of experience, reflection, and learning. While it can be acquired in various ways, it is not always easily obtained. However, there are certain contexts in which wisdom can appear more accessible:
From Teaching and Mentorship: When individuals have access to wise teachers or mentors who share their knowledge and insights, wisdom can be more readily acquired. This is because mentors can provide guidance, share their experiences, and offer perspectives that help learners understand complex concepts more easily.
Through Reflection and Self-Inquiry: Engaging in deep reflection and self-inquir
Wisdom is easily acquired when Wisdom is often considered a deep and nuanced quality that comes from a combination of experience, reflection, and learning. While it can be acquired in various ways, it is not always easily obtained. However, there are certain contexts in which wisdom can seem more accessible or readily available:
From Teaching and Mentorship: When individuals have access to wise teachers, mentors, or elders who share their knowledge and insights, wisdom can be more easily acquired. This is because the transfer of knowledge from someone who has already navigated many life experiences can provide valuable guidance.
Through Reflection and Self-Inquiry: Engaging in deep reflection and self
Wisdom is easily acquired when Wisdom is often considered a deep and nuanced quality that comes from a combination of experience, reflection, and learning. While it can be acquired in various ways, it is not always easily obtained. However, there are certain contexts in which wisdom can appear more accessible or readily available:
From Teaching and Mentorship: When individuals are exposed to the teachings and insights of wise mentors or teachers, wisdom can be more easily acquired. Mentors often distill years of experience and knowledge into teachable moments that can guide others.
Through Reflection and Self-Inquiry: When people take the time to reflect on their experiences, thoughts,
See an example of stochastic sampling for decoding below, controlled by the temperature. Running again 5 times.
prompt = """Wisdom is easily acquired when"""
TEMP = 0.75
for output in generate_outputs(prompt, MODEL, TEMP, max_tokens=128, n=5):
display(Markdown(" ".join([prompt, output])))
display(Markdown("---"))
Wisdom is easily acquired when Wisdom is not always easily acquired, as it often comes from a combination of experience, reflection, and a willingness to learn from both successes and failures. However, there are certain circumstances where wisdom can seem more accessible:
From Teaching and Mentorship: When individuals have access to wise teachers, mentors, or role models who share their knowledge and insights, wisdom can be more readily learned. This is because mentors often distill years of experience into teachable moments that can be more easily understood and applied.
Through Study and Research: Engaging deeply with texts, academic research, and various forms of literature that deal with human experience, ethics
Wisdom is easily acquired when Wisdom is often seen as a deeper understanding of life, a nuanced appreciation for complexities, and a judicious application of knowledge. It’s not merely about accumulating facts or information but involves discernment, reflection, and the ability to make sound judgments. While wisdom can come in many ways, here are some contexts where it is more easily acquired:
Through Experience: Life experiences, both good and bad, offer rich learning opportunities. The more one engages with different situations, the more one is likely to gain insights and wisdom. Learning from mistakes often proves to be a powerful teacher.
From Mentorship: Learning from those who have more
Wisdom is easily acquired when Wisdom is often perceived as something that comes with experience, reflection, and a deep understanding of various life situations. While it can be acquired in many ways, it is often said to be more readily gained under certain conditions:
Through Reflection: When people take time to reflect on their experiences, both good and bad, they often learn valuable lessons. This introspection helps in understanding the consequences of actions and decisions.
From Mistakes: Making mistakes and learning from them is a powerful way to gain wisdom. Each error provides a unique opportunity to understand what not to do in the future.
With Age: As people grow
Wisdom is easily acquired when Wisdom is often perceived as a culmination of knowledge, experience, reflection, and insight. While it can be gained in various ways, it’s often said to be more easily acquired under certain conditions:
Through Reflection: When individuals take the time to reflect deeply on their experiences, both good and bad, they often come to understand the underlying lessons and principles. This introspection helps in integrating knowledge into a coherent understanding of the world.
From Mentorship: Learning from experienced mentors who have accumulated wisdom over time can accelerate the acquisition of wisdom. Mentorship provides a model for thoughtful consideration and often includes the benefit of the mentor’s
Wisdom is easily acquired when Wisdom is often considered a profound and deep quality that comes from a combination of experience, reflection, and learning. However, while the depth and richness of true wisdom cannot be easily acquired overnight, certain conditions and attitudes can facilitate its development more readily:
Open-mindedness: Being open to new ideas, perspectives, and experiences can accelerate the acquisition of wisdom. An open mind is more receptive to learning from others and adapting to new situations.
Curiosity: A natural curiosity drives individuals to explore, question, and understand the world around them. This inquisitive nature often leads to deeper insights and more nuanced understanding.
With the greedy approach you should see less variation between the 5 different answers. Note that, as it is still a stocastic process, you may still see some similar answers. For the sampling approach, with higher temperature, the answers should present more variations.
3.2 Arithmetic reasoning with zero-shot prompting#
In this lab we use an arithmetic reasoning task from GSM8K, a dataset of 8.5K high quality grade school math problems created by human problem writers. This is a reasoning task with a fixed answer, in this case 25 km. The fact that this type of questions have a unique correct answer is why researchers have generally considered greedy decoding to approach them. However, as shown below, Nova Micro is not able to solve the task correctly with greedy generation.
question = """
Question: When I was 16, my sister was half of my age. \
Now, I’m 42. How old is my sister now? Answer with just the number.
Answer:
"""
TEMP = 0.0
display(Markdown(question))
display(Markdown("---"))
display(Markdown(generate_outputs(question, MODEL, TEMP, max_tokens=512)[0]))
Question: When I was 16, my sister was half of my age. Now, I’m 42. How old is my sister now? Answer with just the number. Answer:
21
Try it Yourself!#

Try asking the same question to other models, such as Mistral and check whether they are able to produce the correct answer in the zero-shot scenario with greedy decoding.
############## CODE HERE ####################
############## END OF CODE ##################
3.3 Arithmetic reasoning with chain-of-thought prompting#
As shown in Chain-of-Thought Prompting Elicits Reasoning in Large Language Models by Wei et al. (2022), chain of thought (i.e. asking the system to generate a series of intermediate reasoning steps) can significantly improve the ability of LLMs to perform complex reasoning.
The following pairs of questions and answers can be used as few-shot examples to elicit a full chain of thought prompt for math word problems. This same few-shot prompt is used in both the Chain-of-thought and in the Self-consistency papers to evaluate performance of LLMs in arithmetic reasoning tasks. The prompt contains a series of math questions and answers, where the answer reasons about the arithmetic needed to arrive at the correct answer.
few_shot_arithmetic_examples = """
Question: There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done, there will be 21 trees. How many trees did the grove workers plant today?
Answer: There are 15 trees originally. Then there were 21 trees after some more were planted. So there must have been 21 - 15 = 6. The answer is 6.
Question: If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot?
Answer: There are originally 3 cars. 2 more cars arrive. 3 + 2 = 5. The answer is 5.
Question: Leah had 32 chocolates and her sister had 42. If they ate 35, how many pieces do they have left in total?
Answer: Originally, Leah had 32 chocolates. Her sister had 42. So in total they had 32 + 42 = 74. After eating 35, they had 74 - 35 = 39. The answer is 39.
Question: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny?
Answer: Jason started with 20 lollipops. Then he had 12 after giving some to Denny. So he gave Denny 20 - 12 = 8. The answer is 8.
Question: Shawn has five toys. For Christmas, he got two toys each from his mom and dad. How many toys does he have now?
Answer: Shawn started with 5 toys. If he got 2 toys each from his mom and dad, then that is 4 more toys. 5 + 4 = 9. The answer is 9.
Question: There were nine computers in the server room. Five more computers were installed each day, from monday to thursday. How many computers are now in the server room?
Answer: There were originally 9 computers. For each of 4 days, 5 more computers were added. So 5 * 4 = 20 computers were added. 9 + 20 is 29. The answer is 29.
Question: Michael had 58 golf balls. On tuesday, he lost 23 golf balls. On wednesday, he lost 2 more. How many golf balls did he have at the end of wednesday?
Answer: Michael started with 58 golf balls. After losing 23 on tuesday, he had 58 - 23 = 35. After losing 2 more, he had 35 - 2 = 33 golf balls. The answer is 33.
Question: Olivia has $23. She bought five bagels for $3 each. How much money does she have left?
Answer: Olivia had 23 dollars. 5 bagels for 3 dollars each will be 5 x 3 = 15 dollars. So she has 23 - 15 dollars left. 23 - 15 is 8. The answer is 8.
"""
We assemble the math few-shot examples above with the concrete arithmetic task that we want the model to solve. We prompt Amazon Nova Micro with it and use greedy decoding to generate the most deterministic response. We observe that in this case, despite prompting with chain-of-thought, the model fails at reasoning correctly to arrive at the right answer.
cot_template = """
{few_shot_examples}
{question}
"""
prompt = PromptTemplate.from_template(cot_template).format(
few_shot_examples=few_shot_arithmetic_examples,
question=question
)
display(Markdown(prompt))
display(Markdown("---"))
TEMP = 0.0
Markdown(generate_outputs(prompt, MODEL, TEMP, max_tokens=512)[0])
Question: There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done, there will be 21 trees. How many trees did the grove workers plant today?
Answer: There are 15 trees originally. Then there were 21 trees after some more were planted. So there must have been 21 - 15 = 6. The answer is 6.
Question: If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot?
Answer: There are originally 3 cars. 2 more cars arrive. 3 + 2 = 5. The answer is 5.
Question: Leah had 32 chocolates and her sister had 42. If they ate 35, how many pieces do they have left in total?
Answer: Originally, Leah had 32 chocolates. Her sister had 42. So in total they had 32 + 42 = 74. After eating 35, they had 74 - 35 = 39. The answer is 39.
Question: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny?
Answer: Jason started with 20 lollipops. Then he had 12 after giving some to Denny. So he gave Denny 20 - 12 = 8. The answer is 8.
Question: Shawn has five toys. For Christmas, he got two toys each from his mom and dad. How many toys does he have now?
Answer: Shawn started with 5 toys. If he got 2 toys each from his mom and dad, then that is 4 more toys. 5 + 4 = 9. The answer is 9.
Question: There were nine computers in the server room. Five more computers were installed each day, from monday to thursday. How many computers are now in the server room?
Answer: There were originally 9 computers. For each of 4 days, 5 more computers were added. So 5 * 4 = 20 computers were added. 9 + 20 is 29. The answer is 29.
Question: Michael had 58 golf balls. On tuesday, he lost 23 golf balls. On wednesday, he lost 2 more. How many golf balls did he have at the end of wednesday?
Answer: Michael started with 58 golf balls. After losing 23 on tuesday, he had 58 - 23 = 35. After losing 2 more, he had 35 - 2 = 33 golf balls. The answer is 33.
Question: Olivia has $23. She bought five bagels for $3 each. How much money does she have left?
Answer: Olivia had 23 dollars. 5 bagels for 3 dollars each will be 5 x 3 = 15 dollars. So she has 23 - 15 dollars left. 23 - 15 is 8. The answer is 8.
Question: When I was 16, my sister was half of my age. Now, I’m 42. How old is my sister now? Answer with just the number. Answer:
21
3.4 Arithmetic reasoning with self-consistency#
Next we try the self-consistency method. Since LLMs are not perfect reasoners, they might produce an incorrect reasoning path or make a mistake in one of the reasoning steps, as seen in the CoT example above. However, it is hypothesized that diverse reasoning processes are likely to produce correct responses in a majority of the cases. Even when the desired answer is fixed, introducing diversity in the reasoning processes can be highly beneficial; therefore we leverage sampling, as commonly used for open-ended text generation, to achieve this goal.
Self-consistency prompting follows a “sample-and-marginalize” decoding procedure:
first sample from the LLM’s decoder to generate a diverse set of outputs
each reasoning path might lead to a different final answer
the optimal answer is determined by finding the most consistent one in the response set.
To sample diverse reasoning paths, we follow similar settings to those suggested in the Self-consistency paper, i.e. we apply temperature sampling, for instance T=0.5.
Let’s produce a set of answers to the prompt using temperature sampling. We can see that some of the responses are correct, and a majority seems to be emerging. Note that the generated outputs vary each time. It might be that you don’t see a majority of correct answers when sampling 10 responses. As the Amazon Micro model may not have the needed performance for this self-consistency experiment, let’s use Amazon Lite instead, a more performatic model.
MODEL = "amazon.nova-lite-v1:0"
T_SAMPLE = 0.5
completions = generate_outputs(prompt, MODEL, T_SAMPLE, max_tokens=128, n=10)
for completion in completions:
display(Markdown(completion))
display(Markdown("---"))
When you were 16, your sister was 16 / 2 = 8. Now, 42 - 16 = 26 years have passed. So your sister is now 8 + 26 = 34. The answer is 34.
When you were 16, your sister was half your age, which means she was 16 / 2 = 8 years old. Now, you are 42, which means 42 - 16 = 26 years have passed. That means your sister is now 8 + 26 = 34 years old. The answer is 34.
When you were 16, your sister was 8 years old. Now, when you’re 42, your sister is 42 - 16 + 8 = 34. The answer is 34.
When the narrator was 16, their sister was half their age, which means the sister was 16 / 2 = 8 years old at that time. Now, the narrator is 42, and since the sister was 8 years younger, she is now 42 - 8 = 34 years old. The answer is 34.
When you were 16, your sister was half your age, which means she was 16 / 2 = 8 years old. Now, you are 42, which means 42 - 16 = 26 years have passed. So your sister is now 8 + 26 = 34 years old. The answer is 34.
Explanation: When you were 16, your sister was half your age, which means she was 8 years old at that time. Now, you are 42, which means 26 years have passed since you were 16 (42 - 16 = 26). Since your sister is 8 years younger than you, she is now 32 years old (26 + 8 = 32).
When the sister was 26, the person was 16. That means the age difference between them is 16 - 26 = 10 years. So, the sister’s current age is 42 - 10 = 32 years. The answer is 32.
The answer is 32.
When you were 16, your sister was half your age, meaning she was 16 / 2 = 8 years old. Now, 26 years have passed (from 16 to 42), so your sister is 8 + 26 = 34 years old. The answer is 34.
4. Evaluation of results#
To fully evaluate the performance of self-consistency, we create a helper function to extract the numerical answer from the LLM output. We implement a simple regex search, first looking for instances of Answer followed by a number. In the absence of a match, we observe that the relevant answer tends to be the last number that is produced in the response string. This captures the majority of the observed cases.
def extract_answer(text:str) -> int:
"""
Parser to extract the numerical answer to the math task
"""
answer = None
# Pattern to find "Answer *** Number"
pattern1 = r".*[aA]nswer.*?(\d+)"
# Pattern to find the last number in a string
pattern2 = r"(\d+)(?=\D*$)"
# Try with first pattern
match = re.findall(pattern1, text, re.DOTALL)
if match:
answer = int(match[0])
else:
# Try with second pattern
match = re.findall(pattern2, text, re.DOTALL)
if match:
answer = int(match[0])
return answer
Let’s check that the parser function correctly extracts the numerical answer from the responses generated above.
[extract_answer(c) for c in completions]
[34, 34, 34, 34, 32, 34, 32, 32, 32, 34]
We check the performance of the self-consistency method by running 3 rounds of text generation, each with 20 generated outputs. We then extract the majority vote as the correct answer. To ensure robustness of results, we sample at 3 different temperatures.
T_SAMPLE = [0.5, 0.6, 0.7]
completions = {}
answers = {}
for gen_round in range(3):
completions[gen_round] = generate_outputs(
prompt,
MODEL, T_SAMPLE[gen_round],
max_tokens=128,
# stop_sequences=["Question:"],
n=10
)
answers[gen_round] = [extract_answer(c) for c in completions[gen_round]]
counts = Counter(answers[gen_round])
majority_answer = counts.most_common(1)[0][0]
print(f"Temperature: {T_SAMPLE[gen_round]}")
print(f"Majority answer: {majority_answer}")
print("")
Temperature: 0.5
Majority answer: 34
Temperature: 0.6
Majority answer: 34
Temperature: 0.7
Majority answer: 34
Conclusion#
The self-consistency method may or may not be able to obtain the correct answer (34-years old) in all three rounds depending on the model of choice. Please notice that depending on the particular scenario, CoT prompting, and models used, results and performance of this approach might vary.
Try it Yourself!#

Well done on completing the lab. Now it's time for you to get creative.
Try running the method to solve other arithmetic reasoning tasks as can be found in the GSM8K dataset.
############## CODE HERE ####################
############## END OF CODE ##################
5. Quiz Questions#
Well done on completing the lab! Now, it’s time for a brief knowledge assessment.

Try it Yourself!#
Answer the following questions to test your understanding of self-consistency prompting.
from mlu_utils.quiz_questions import *
lab4a_question1.display()