Lab 3a: Retrieval Augmented Generation#
In this notebook, we will apply Retrieval Augmented Generation (RAG) to adapt an LLM to a specific task. Many applications require task-specific data which may not be a part of the LLM’s training data. Additionally, relevant context may undergo contant changes or fluctuations such as weather or stock prices, among others. RAG involves retrieving data from relevant and reliable sources and augmenting the context of the prompt in order to generate the desired response. LangChain provides several modules to implement a RAG workflow.
Table of contents#
Please work top to bottom of this notebook and don’t skip sections as this could lead to error messages due to missing code.
About This Lab#
Throughout this lab, you will encounter two types of interactive elements:


No coding is needed for an activity. You try to understand a concept, answer questions, or run a code cell.
Challenges are where you test your understanding by implementing something new or taking a short quiz.
Please work through this notebook from top to bottom to avoid errors due to missing code or context.
1. Setup and configuration#
1.1 Install and import dependencies#
First, let’s install and import the necessary libraries, including the LangChain library
%%capture
!pip3 install -r ../requirements.txt --quiet
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
import sys
sys.path.append('..')
import boto3
import json
import warnings
from IPython.display import Markdown
import re
import random
import pandas as pd
warnings.filterwarnings("ignore")
1.2. Validate LLM model access#
As a first step we need to verify that the LLM models required in this lab are accessible. Lets do that now by using the helper function validate_models_access and provide the list of LLM models that we require for this lab. If the call to validate_models_access returns any model ids in the output list then you will need to go to the Amazon Bedrock console and enable access to the required models.
from mlu_utils.helpers import validate_models_access
if not validate_models_access(["amazon.nova-lite-v1:0", "mistral.mixtral-8x7b-instruct-v0:1", "amazon.nova-lite-v1:0"]):
print("The models are accessible. You can go ahead running this notebook.")
The models are accessible. You can go ahead running this notebook.
2. Document loaders#
Document loaders are used to load data from external sources as Documents. A Document is a piece of text and associated metadata. LangChain offers a number of other document loaders and integrations. Some noticeable LangChain document loaders are:
S3FileLoaderS3DirectoryLoaderAmazonTextractPDFLoaderCSVLoader

Activity: Try different document loaders#
Try different document loaders and different prompts for the retrieval chains in the notebook.
Note: Results may not be factually accurate and may be based on false assumptions.
2.1 URL loader#
For this notebook, we will load an AWS blogpost on Bedrock Agents as the external source.
import nltk
nltk.download("punkt_tab")
nltk.download("averaged_perceptron_tagger_eng")
[nltk_data] Downloading package punkt_tab to /home/sagemaker-
[nltk_data] user/nltk_data...
[nltk_data] Package punkt_tab is already up-to-date!
[nltk_data] Downloading package averaged_perceptron_tagger_eng to
[nltk_data] /home/sagemaker-user/nltk_data...
[nltk_data] Package averaged_perceptron_tagger_eng is already up-to-
[nltk_data] date!
True
from langchain.document_loaders import UnstructuredURLLoader
# List of URLs for the loader. We will only use one in this example.
urls = [
"https://aws.amazon.com/blogs/machine-learning/amazon-bedrock-announces-general-availability-of-multi-agent-collaboration/",
]
# Define the URL Loader
loader = UnstructuredURLLoader(urls=urls)
# Load the data
data = loader.load()
# Pre-process the content a bit
data[0].page_content = re.sub("\n{3,}", "\n", data[0].page_content)
data[0].page_content = re.sub(" {2,}", " ", data[0].page_content)
Let’s display the content of the page.
Markdown(data[0].page_content)
Artificial Intelligence
Amazon Bedrock announces general availability of multi-agent collaboration
by Sri Koneru on 10 MAR 2025 in Amazon Bedrock, Amazon Bedrock Agents, Announcements, Generative AI, Launch Permalink Comments Share
Today, we’re announcing the general availability (GA) of multi-agent collaboration on Amazon Bedrock. This capability allows developers to build, deploy, and manage networks of AI agents that work together to execute complex, multi-step workflows efficiently.
Since its preview launch at re:Invent 2024, organizations across industries—including financial services, healthcare, supply chain and logistics, manufacturing, and customer support—have used multi-agent collaboration to orchestrate specialized agents, driving efficiency, accuracy, and automation. With this GA release, we’ve introduced enhancements based on customer feedback, further improving scalability, observability, and flexibility—making AI-driven workflows easier to manage and optimize.
What is multi-agent collaboration?
Generative AI is no longer just about models generating responses, it’s about automation. The next wave of innovation is driven by agents that can reason, plan, and act autonomously across company systems. Generative AI applications are no longer just generating content; they also take action, solve problems, and execute complex workflows. The shift is clear: businesses need AI that doesn’t just respond to prompts but orchestrates entire workflows, automating processes end to end.
Agents enable generative AI applications to perform tasks across company systems and data sources, and Amazon Bedrock already simplifies building them. With Amazon Bedrock, customers can quickly create agents that handle sales orders, compile financial reports, analyze customer retention, and much more. However, as applications become more capable, the tasks customers want them to perform can exceed what a single agent can manage—either because the tasks require specialized expertise, involve multiple steps, or demand continuous execution over time.
Coordinating potentially hundreds of agents at scale is also challenging, because managing dependencies, ensuring efficient task distribution, and maintaining performance across a large network of specialized agents requires sophisticated orchestration. Without the right tools, businesses can face inefficiencies, increased latency, and difficulties in monitoring and optimizing performance. For customers looking to advance their agents and tackle more intricate, multi-step workflows, Amazon Bedrock supports multi-agent collaboration, enabling developers to easily build, deploy, and manage multiple specialized agents working together seamlessly.
Multi-agent collaboration enables developers to create networks of specialized agents that communicate and coordinate under the guidance of a supervisor agent. Each agent contributes its expertise to the larger workflow by focusing on a specific task. This approach breaks down complex processes into manageable sub-tasks processed in parallel. By facilitating seamless interaction among agents, Amazon Bedrock enhances operational efficiency and accuracy, ensuring workflows run more effectively at scale. Because each agent only accesses the data required for its role, this approach minimizes exposure of sensitive information while reinforcing security and governance. This allows businesses to scale their AI-driven workflows without the need for manual intervention in coordinating agents. As more agents are added, the supervisor ensures smooth collaboration between them all.
By using multi-agent collaboration on Amazon Bedrock, organizations can:
Streamline AI-driven workflows by distributing workloads across specialized agents.
Improve execution efficiency by parallelizing tasks where possible.
Enhance security and governance by restricting agent access to only necessary data.
Reduce operational complexity by eliminating manual intervention in agent coordination.
A key challenge in building effective multi-agent collaboration systems is managing the complexity and overhead of coordinating multiple specialized agents at scale. Amazon Bedrock simplifies the process of building, deploying, and orchestrating effective multi-agent collaboration systems while addressing efficiency challenges through several key features and optimizations:
Quick setup – Create, deploy, and manage AI agents working together in minutes without the need for complex coding.
Composability – Integrate your existing agents as subagents within a larger agent system, allowing them to seamlessly work together to tackle complex workflows.
Efficient inter-agent communication – The supervisor agent can interact with subagents using a consistent interface, supporting parallel communication for more efficient task completion.
Optimized collaboration modes – Choose between supervisor mode and supervisor with routing mode. With routing mode, the supervisor agent will route simple requests directly to specialized subagents, bypassing full orchestration. For complex queries or when no clear intention is detected, it automatically falls back to the full supervisor mode, where the supervisor agent analyzes, breaks down problems, and coordinates multiple subagents as needed.
Integrated trace and debug console – Visualize and analyze multi-agent interactions behind the scenes using the integrated trace and debug console.
What’s new in general availability?
The GA release introduces several key enhancements based on customer feedback, making multi-agent collaboration more scalable, flexible, and efficient:
Inline agent support – Enables the creation of supervisor agents dynamically at runtime, allowing for more flexible agent management without predefined structures.
AWS CloudFormation and AWS Cloud Development Kit (AWS CDK) support – Enables customers to deploy agent networks as code, enabling scalable, reusable agent templates across AWS accounts.
Enhanced traceability and debugging – Provides structured execution logs, sub-step tracking, and Amazon CloudWatch integration to improve monitoring and troubleshooting.
Increased collaborator and step count limits – Expands self-service limits for agent collaborators and execution steps, supporting larger-scale workflows.
Payload referencing – Reduces latency and costs by allowing the supervisor agent to reference external data sources without embedding them in the agent request.
Improved citation handling – Enhances accuracy and attribution when agents pull external data sources into their responses.
These features collectively improve coordination capabilities, communication speed, and overall effectiveness of the multi-agent collaboration framework in tackling complex, real-world problems.
Multi-agent collaboration across industries
Multi-agent collaboration is already transforming AI automation across sectors:
Investment advisory – A financial firm uses multiple agents to analyze market trends, risk factors, and investment opportunities to deliver personalized client recommendations.
Retail operations – A retailer deploys agents for demand forecasting, inventory tracking, pricing optimization, and order fulfillment to increase operational efficiency.
Fraud detection – A banking institution assigns agents to monitor transactions, detect anomalies, validate customer behaviors, and flag potential fraud risks in real time.
Customer support – An enterprise customer service platform uses agents for sentiment analysis, ticket classification, knowledge base retrieval, and automated responses to enhance resolution times.
Healthcare diagnosis – A hospital system integrates agents for patient record analysis, symptom recognition, medical imaging review, and treatment plan recommendations to assist clinicians.
Deep dive: Syngenta’s use of multi-agent collaboration
Syngenta, a global leader in agricultural innovation, has integrated cutting-edge generative AI into its Cropwise service, resulting in the development of Cropwise AI. This advanced system is designed to enhance the efficiency of agronomic advisors and growers by providing tailored recommendations for crop management practices.
Business challenge
The agricultural sector faces the complex task of optimizing crop yields while ensuring sustainability and profitability. Farmers and agronomic advisors must consider a multitude of factors, including weather patterns, soil conditions, crop growth stages, and potential pest and disease threats. In the past, analyzing these variables required extensive manual effort and expertise. Syngenta recognized the need for a more efficient, data-driven approach to support decision-making in crop management.
Solution: Cropwise AI
To address these challenges, Syngenta collaborated with AWS to develop Cropwise AI, using Amazon Bedrock Agents to create a multi-agent system that integrates various data sources and AI capabilities. This system offers several key features:
Advanced seed recommendation and placement – Uses predictive machine learning algorithms to deliver personalized seed recommendations tailored to each grower’s unique environment.
Sophisticated predictive modeling – Employs state-of-the-art machine learning algorithms to forecast crop growth patterns, yield potential, and potential risk factors by integrating real-time data with comprehensive historical information.
Precision agriculture optimization – Provides hyper-localized, site-specific recommendations for input application, minimizing waste and maximizing resource efficiency.
Agent architecture
Cropwise AI is built on AWS architecture and designed for scalability, maintainability, and security. The system uses Amazon Bedrock Agents to orchestrate multiple AI agents, each specializing in distinct tasks:
Data aggregation agent – Collects and integrates extensive datasets, including over 20 years of weather history, soil conditions, and more than 80,000 observations on crop growth stages.
Recommendation agent – Analyzes the aggregated data to provide tailored recommendations for precise input applications, product placement, and strategies for pest and disease control.
Conversational AI agent – Uses a multilingual conversational large language model (LLM) to interact with users in natural language, delivering insights in a clear format.
This multi-agent collaboration enables Cropwise AI to process complex agricultural data efficiently, offering actionable insights and personalized recommendations to enhance crop yields, sustainability, and profitability.
Results
By implementing Cropwise AI, Syngenta has achieved significant improvements in agricultural practices:
Enhanced decision-making: Agronomic advisors and growers receive data-driven recommendations, leading to optimized crop management strategies.
Increased yields: Utilizing Syngenta’s seed recommendation models, Cropwise AI helps growers increase yields by up to 5%.
Sustainable practices: The system promotes precision agriculture, reducing waste and minimizing environmental impact through optimized input applications.
Highlighting the significance of this advancement, Feroz Sheikh, Chief Information and Digital Officer at Syngenta Group, stated:
“Agricultural innovation leader Syngenta is using Amazon Bedrock Agents as part of its Cropwise AI solution, which gives growers deep insights to help them optimize crop yields, improve sustainability, and drive profitability. With multi-agent collaboration, Syngenta will be able to use multiple agents to further improve their recommendations to growers, transforming how their end-users make decisions and delivering even greater value to the farming community.”
This collaboration between Syngenta and AWS exemplifies the transformative potential of generative AI and multi-agent systems in agriculture, driving innovation and supporting sustainable farming practices.
How multi-agent collaboration works
Amazon Bedrock automates agent collaboration, including task delegation, execution tracking, and data orchestration. Developers can configure their system in one of two collaboration modes:
Supervisor mode
The supervisor agent receives an input, breaks down complex requests, and assigns tasks to specialized sub-agents.
Sub-agents execute tasks in parallel or sequentially, returning responses to the supervisor, which consolidates the results.
Supervisor with routing mode
Simple queries are routed directly to a relevant sub-agent.
Complex or ambiguous requests trigger the supervisor to coordinate multiple agents to complete the task.
Watch the Amazon Bedrock multi-agent collaboration video to learn how to get started.
Conclusion
By enabling seamless multi-agent collaboration, Amazon Bedrock empowers businesses to scale their generative AI applications with greater efficiency, accuracy, and flexibility. As organizations continue to push the boundaries of AI-driven automation, having the right tools to orchestrate complex workflows will be essential. With Amazon Bedrock, companies can confidently build AI systems that don’t just generate responses but drive real impact—automating processes, solving problems, and unlocking new possibilities across industries.
Amazon Bedrock multi-agent collaboration is now generally available.
Learn more: Automate tasks in your application using AI agents
Code samples: Amazon Bedrock agent samples on GitHub
Try it out today in the AWS Management Console for Amazon Bedrock.
Multi-agent collaboration opens new possibilities for AI-driven automation. Whether in finance, healthcare, retail, or agriculture, Amazon Bedrock helps organizations scale AI workflows with efficiency and precision.
Start building today—and let us know what you create!
About the authors Sri Koneru has spent the last 13.5 years honing her skills in both cutting-edge product development and large-scale infrastructure. At Salesforce for 7.5 years, she had the incredible opportunity to build and launch brand new products from the ground up, reaching over 100,000 external customers. This experience was instrumental in her professional growth. Then, at Google for 6 years, she transitioned to managing critical infrastructure, overseeing capacity, efficiency, fungibility, job scheduling, data platforms, and spatial flexibility for all of Alphabet. Most recently, Sri joined Amazon Web Services leveraging her diverse skillset to make a significant impact on AI/ML services and infrastructure at AWS. Personally, Sri & her husband recently became empty nesters, relocating to Seattle from the Bay Area. They’re a basketball-loving family who even catch pre-season Warriors games but are looking forward to cheering on the Seattle Storm this year. Beyond basketball, Sri enjoys cooking, recipe creation, reading, and her newfound hobby of hiking. While she’s a sun-seeker at heart, she is looking forward to experiencing the unique character of Seattle weather.
Loading comments…
2.2 PDF loader#
You can use the PDFLoader to load text from PDFs along with relevant metadata such as page number, document name, etc.
The PDFLoader requires the pypdf library to function.
We will read the sample PDF file of a the well-known paper “Attention Is All You Need” paper by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. This research paper laid out the foundations of the transformers models that power many generative AI applications nowadays. Paper linked here. The paper is 11 pages long.
from langchain.document_loaders import PyPDFLoader
# Define the PDF loader
pdf_loader = PyPDFLoader("data/transformers_paper.pdf")
# Load data from the pdf
pages = pdf_loader.load()
# Observe number of pages loaded
print("Number of pages loaded: {} \n".format(len(pages)))
# Print contents of the 90th page
Markdown(pages[0].page_content)
Number of pages loaded: 11
Attention Is All You Need Ashish Vaswani∗ Google Brain avaswani@google.com Noam Shazeer∗ Google Brain noam@google.com Niki Parmar∗ Google Research nikip@google.com Jakob Uszkoreit∗ Google Research usz@google.com Llion Jones∗ Google Research llion@google.com Aidan N. Gomez∗† University of Toronto aidan@cs.toronto.edu Łukasz Kaiser∗ Google Brain lukaszkaiser@google.com Illia Polosukhin∗‡ illia.polosukhin@gmail.com Abstract The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English- to-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.0 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. 1 Introduction Recurrent neural networks, long short-term memory [12] and gated recurrent [7] neural networks in particular, have been firmly established as state of the art approaches in sequence modeling and transduction problems such as language modeling and machine translation [ 29, 2, 5]. Numerous efforts have since continued to push the boundaries of recurrent language models and encoder-decoder architectures [31, 21, 13]. ∗Equal contribution. Listing order is random. Jakob proposed replacing RNNs with self-attention and started the effort to evaluate this idea. Ashish, with Illia, designed and implemented the first Transformer models and has been crucially involved in every aspect of this work. Noam proposed scaled dot-product attention, multi-head attention and the parameter-free position representation and became the other person involved in nearly every detail. Niki designed, implemented, tuned and evaluated countless model variants in our original codebase and tensor2tensor. Llion also experimented with novel model variants, was responsible for our initial codebase, and efficient inference and visualizations. Lukasz and Aidan spent countless long days designing various parts of and implementing tensor2tensor, replacing our earlier codebase, greatly improving results and massively accelerating our research. †Work performed while at Google Brain. ‡Work performed while at Google Research. 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA.
2.3 Wikipedia loader#
The WikipediaLoader requires the wikipedia library to function.
from langchain.document_loaders import WikipediaLoader
# Define the Wikipedia Loader
wiki_loader = WikipediaLoader(query="Generative AI", load_max_docs=1)
# Load pages from Wikipedia based on the query
try:
wiki_doc = wiki_loader.load()
display(Markdown(wiki_doc[0].page_content))
except Exception as e:
print(f"⚠️ Could not load Wikipedia content. This may be due to network restrictions in this environment.")
print(f"Error: {e}")
Generative artificial intelligence (GenAI) is a subfield of artificial intelligence (AI) that uses generative models to generate text, images, videos, audio, software code (vibe coding) or other forms of data. These models learn the underlying patterns and structures of their training data, and use them to generate new data in response to input, which often takes the form of natural language prompts.
The prevalence of generative AI tools has increased significantly since the AI boom in the 2020s. This boom was made possible by improvements in deep neural networks, particularly large language models (LLMs), which are based on the transformer architecture. Generative AI applications include chatbots such as ChatGPT, Claude, Copilot, DeepSeek, Doubao, Google Gemini, Grok and Qwen; text-to-image models such as DALL-E, Firefly, Stable Diffusion, and Midjourney; and text-to-video models such as Veo, LTX and Sora.
Companies in a variety of sectors have used generative AI, including those in software development, healthcare, finance, entertainment, customer service, sales and marketing, art, writing, and product design.
Generative AI has been used for cybercrime, and to deceive and manipulate people through fake news and deepfakes. Generative AI models have been trained on copyrighted works without the rightholders’ permission. Many generative AI systems use large-scale data centers, whose environmental impacts include electronic waste, consumption of fresh water for cooling, and high energy consumption that is estimated to be growing steadily.
== History ==
=== Early history === The origins of algorithmically generated media can be traced to the development of the Markov chain, which has been used to model natural language since the early 20th century. Russian mathematician Andrey Markov introduced the concept in 1906, including an analysis of vowel and consonant patterns in Eugeny Onegin. Once trained on a text corpus, a Markov chain can generate probabilistic text. By the early 1970s, artists began using computers to extend generative techniques beyond Markov models. Harold Cohen developed and exhibited works produced by AARON, a pioneering computer program designed to autonomously create paintings. The terms generative AI planning or generative planning were used in the 1980s and 1990s to refer to AI planning systems, especially computer-aided process planning, used to generate sequences of actions to reach a specified goal. Generative AI planning systems used symbolic AI methods such as state space search and constraint satisfaction and were a “relatively mature” technology by the early 1990s. They were used to generate crisis action plans for military use, process plans for manufacturing and decision plans such as in prototype autonomous spacecraft.
=== Generative neural networks (since the late 2000s) ===
Machine learning uses both discriminative models and generative models to predict or generate data. Beginning in the late 2000s and early 2010s, advances in deep learning led to major improvements in image classification, speech recognition, and natural language processing. Neural networks in this period were typically trained as discriminative models due to the relative difficulty of training generative models. In 2014, the introduction of models such as the variational autoencoder (VAE) and generative adversarial network (GAN) enabled effective deep generative modeling of complex data such as images. In 2017, the Transformer architecture enabled further advances in generative modeling compared to earlier long short-term memory (LSTM) networks. This led to the development of generative pre-trained transformer (GPT) models, beginning with GPT-1 in 2018.
=== Generative AI adoption ===
In March 2020, the release of 15.ai, a free web application created by an anonymous MIT researcher that could generate convincing character voices using minimal training data, was one of the earliest publicly available uses for generat
3. Document splitters#
Large documents may pose a challenge for RAG as they might not fit into the context window. Document splitting is often performed to separate large documents into smaller chunks. This also allows the retriever to select the more relevant chunks from the document instead of feeding the entire data to an LLM.
LangChain offers several modules for effectively splitting documents. In this section, we will use the RecursiveCharacterTextSplitter, which is also the default text splitter.
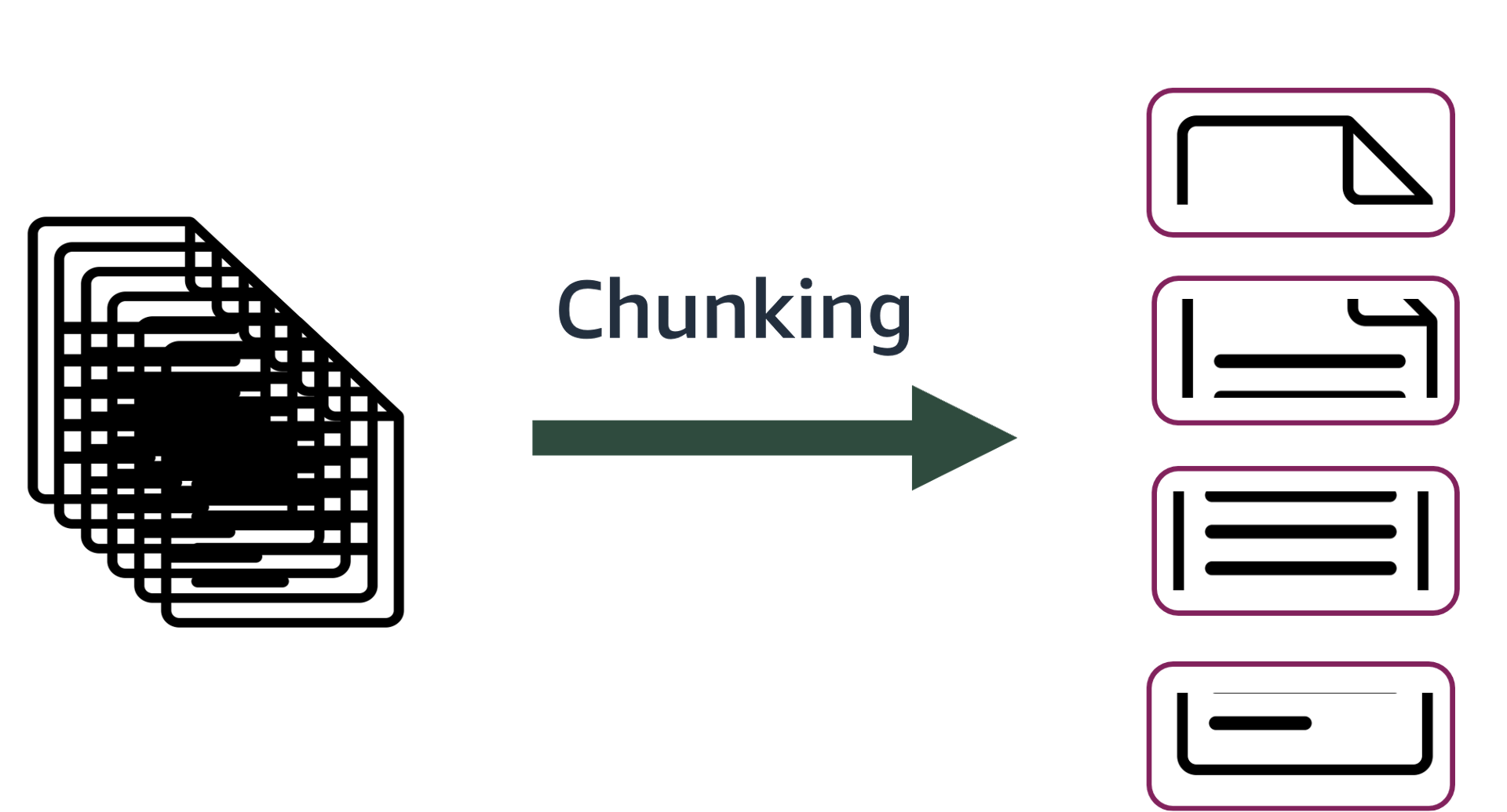
from mlu_utils.widgets.text_splitters import create_text_splitter_widget
create_text_splitter_widget()
from langchain.text_splitter import (
RecursiveCharacterTextSplitter,
CharacterTextSplitter,
)
# Use the recursive character splitter
recur_splitter = RecursiveCharacterTextSplitter(
chunk_size=1200,
chunk_overlap=60,
separators=["\n\n", "\n", "(?<=\. )", " ", ""],
is_separator_regex=True,
)
# Perform the splits using the splitter
data_splits = recur_splitter.split_documents(data)
# Print a random chunk
print(random.choice(data_splits).page_content)
About the authors
Sri Koneru has spent the last 13.5 years honing her skills in both cutting-edge product development and large-scale infrastructure. At Salesforce for 7.5 years, she had the incredible opportunity to build and launch brand new products from the ground up, reaching over 100,000 external customers. This experience was instrumental in her professional growth. Then, at Google for 6 years, she transitioned to managing critical infrastructure, overseeing capacity, efficiency, fungibility, job scheduling, data platforms, and spatial flexibility for all of Alphabet. Most recently, Sri joined Amazon Web Services leveraging her diverse skillset to make a significant impact on AI/ML services and infrastructure at AWS. Personally, Sri & her husband recently became empty nesters, relocating to Seattle from the Bay Area. They’re a basketball-loving family who even catch pre-season Warriors games but are looking forward to cheering on the Seattle Storm this year. Beyond basketball, Sri enjoys cooking, recipe creation, reading, and her newfound hobby of hiking. While she’s a sun-seeker at heart, she is looking forward to experiencing the unique character of Seattle weather.
4. Vector stores#
Since the split chunks need to be retrieved based on semantic relevance, using embeddings serves better than storing the chunks as text. At query time, the query is transformed into an embedding and used to find other similar chunk embeddings to retrieve related chunks.
To store these embeddings for search and retrieval, we use vector stores.
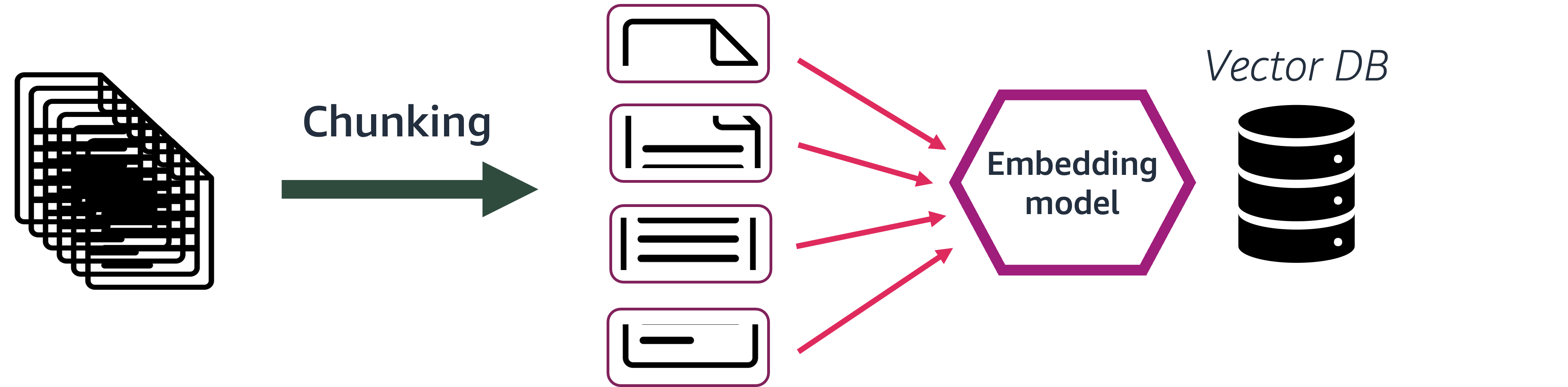
4.1 Embedding model#
An embedding model is required to transform the text into vectors represented using embeddings. We will be using the Amazon Nova 2 Multimodal Embeddings Model to vectorize the chunks.
from langchain_core.embeddings import Embeddings
from typing import List
# Define the bedrock client
bedrock = boto3.client(
service_name="bedrock",
region_name="us-east-1",
endpoint_url="https://bedrock.us-east-1.amazonaws.com",
)
# Define the bedrock-runtime client that will be used for predictions
bedrock_runtime = boto3.client(service_name="bedrock-runtime")
# Custom Nova Embeddings class for LangChain
class NovaMultimodalEmbeddings(Embeddings):
"""Custom embeddings class for Amazon Nova 2 Multimodal Embeddings"""
def __init__(self, client, model_id="amazon.nova-2-multimodal-embeddings-v1:0", dimension=1024):
self.client = client
self.model_id = model_id
self.dimension = dimension
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""Embed a list of documents (texts)"""
embeddings = []
for text in texts:
body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingDimension": self.dimension,
"embeddingPurpose": "GENERIC_INDEX",
"text": {
"truncationMode": "END",
"value": text
}
}
}
response = self.client.invoke_model(
modelId=self.model_id,
body=json.dumps(body)
)
result = json.loads(response['body'].read())
embeddings.append(result['embeddings'][0]['embedding'])
return embeddings
def embed_query(self, text: str) -> List[float]:
"""Embed a single query text"""
body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingDimension": self.dimension,
"embeddingPurpose": "GENERIC_RETRIEVAL", # Use RETRIEVAL for queries
"text": {
"truncationMode": "END",
"value": text
}
}
}
response = self.client.invoke_model(
modelId=self.model_id,
body=json.dumps(body)
)
result = json.loads(response['body'].read())
return result['embeddings'][0]['embedding']
# Define the bedrock embeddings model using Nova 2 Multimodal Embeddings
bedrock_embeddings = NovaMultimodalEmbeddings(
client=bedrock_runtime,
model_id="amazon.nova-2-multimodal-embeddings-v1:0",
dimension=1024
)
4.2 Define the vector store#
We will now use the embedding model to generate the embeddings and store them in the vector database. In this example, we will use FAISS (Facebook AI Similarity Search), which is a lightweight vector database that can be run locally. It provides efficient similarity search and clustering of dense vectors.
from langchain.vectorstores import FAISS
# Create a vector DB from documents retrieved from the URL and split with the RecursiveCharacterTextSplitter
vectordb = FAISS.from_documents(
data_splits,
bedrock_embeddings,
)
# Query to retrieve similar chunks
query = "What is supervisor mode?"
# Retrieve similar chunks based on relevance. We only retrieve 'k' most similar chunks
similar_chunks = vectordb.similarity_search_with_relevance_scores(query, k=4)
# Format document to text format
retrieved_text = [chunk[0].page_content for chunk in similar_chunks]
relevance_score = [chunk[1] for chunk in similar_chunks]
# Store and print as a dataframe
retrieved_chunks = pd.DataFrame(
list(zip(retrieved_text, relevance_score)),
columns=["Retrieved Chunks", "Relevance Score"],
)
with pd.option_context("display.max_colwidth", None):
display(retrieved_chunks)
| Retrieved Chunks | Relevance Score | |
|---|---|---|
| 0 | Optimized collaboration modes – Choose between supervisor mode and supervisor with routing mode. With routing mode, the supervisor agent will route simple requests directly to specialized subagents, bypassing full orchestration. For complex queries or when no clear intention is detected, it automatically falls back to the full supervisor mode, where the supervisor agent analyzes, breaks down problems, and coordinates multiple subagents as needed.\n\nIntegrated trace and debug console – Visualize and analyze multi-agent interactions behind the scenes using the integrated trace and debug console.\n\nWhat’s new in general availability?\n\nThe GA release introduces several key enhancements based on customer feedback, making multi-agent collaboration more scalable, flexible, and efficient:\n\nInline agent support – Enables the creation of supervisor agents dynamically at runtime, allowing for more flexible agent management without predefined structures.\n\nAWS CloudFormation and AWS Cloud Development Kit (AWS CDK) support – Enables customers to deploy agent networks as code, enabling scalable, reusable agent templates across AWS accounts. | 0.013453 |
| 1 | “Agricultural innovation leader Syngenta is using Amazon Bedrock Agents as part of its Cropwise AI solution, which gives growers deep insights to help them optimize crop yields, improve sustainability, and drive profitability. With multi-agent collaboration, Syngenta will be able to use multiple agents to further improve their recommendations to growers, transforming how their end-users make decisions and delivering even greater value to the farming community.”\n\nThis collaboration between Syngenta and AWS exemplifies the transformative potential of generative AI and multi-agent systems in agriculture, driving innovation and supporting sustainable farming practices.\n\nHow multi-agent collaboration works\n\nAmazon Bedrock automates agent collaboration, including task delegation, execution tracking, and data orchestration. Developers can configure their system in one of two collaboration modes:\n\nSupervisor mode\n\nThe supervisor agent receives an input, breaks down complex requests, and assigns tasks to specialized sub-agents.\n\nSub-agents execute tasks in parallel or sequentially, returning responses to the supervisor, which consolidates the results.\n\nSupervisor with routing mode | -0.036316 |
| 2 | Supervisor with routing mode\n\nSimple queries are routed directly to a relevant sub-agent.\n\nComplex or ambiguous requests trigger the supervisor to coordinate multiple agents to complete the task.\n\nWatch the Amazon Bedrock multi-agent collaboration video to learn how to get started.\n\nConclusion\n\nBy enabling seamless multi-agent collaboration, Amazon Bedrock empowers businesses to scale their generative AI applications with greater efficiency, accuracy, and flexibility. As organizations continue to push the boundaries of AI-driven automation, having the right tools to orchestrate complex workflows will be essential. With Amazon Bedrock, companies can confidently build AI systems that don’t just generate responses but drive real impact—automating processes, solving problems, and unlocking new possibilities across industries.\n\nAmazon Bedrock multi-agent collaboration is now generally available.\n\nLearn more: Automate tasks in your application using AI agents\n\nCode samples: Amazon Bedrock agent samples on GitHub\n\nTry it out today in the AWS Management Console for Amazon Bedrock. | -0.039995 |
| 3 | Multi-agent collaboration enables developers to create networks of specialized agents that communicate and coordinate under the guidance of a supervisor agent. Each agent contributes its expertise to the larger workflow by focusing on a specific task. This approach breaks down complex processes into manageable sub-tasks processed in parallel. By facilitating seamless interaction among agents, Amazon Bedrock enhances operational efficiency and accuracy, ensuring workflows run more effectively at scale. Because each agent only accesses the data required for its role, this approach minimizes exposure of sensitive information while reinforcing security and governance. This allows businesses to scale their AI-driven workflows without the need for manual intervention in coordinating agents. As more agents are added, the supervisor ensures smooth collaboration between them all.\n\nBy using multi-agent collaboration on Amazon Bedrock, organizations can:\n\nStreamline AI-driven workflows by distributing workloads across specialized agents.\n\nImprove execution efficiency by parallelizing tasks where possible.\n\nEnhance security and governance by restricting agent access to only necessary data. | -0.068549 |
4.3 Re-rankers#
Re-rankers are used to reorder the documents based on relevance between the documents and the query. Rerankers are slower but much more accurate than embedding models, which makes them ideal for post-retrieval processing rather than for retrieval tasks.
We will use FlashRank, a lightweight, fast library to add re-ranking to your existing search and retrieval pipelines.
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import FlashrankRerank
query = "What is supervisor mode?"
ranker = FlashrankRerank()
updated_retriever = ContextualCompressionRetriever(
base_compressor=ranker, base_retriever=vectordb.as_retriever(search_kwargs={'k': 5})
)
retrieved_docs = updated_retriever.invoke(query)
retrieved_text = [doc.page_content for doc in retrieved_docs]
relevance_score = [doc.metadata['relevance_score'] for doc in retrieved_docs]
# Store and print as a dataframe
retrieved_chunks = pd.DataFrame(
list(zip(retrieved_text, relevance_score)),
columns=["Retrieved Chunks", "Reranked Relevance Score"],
)
with pd.option_context("display.max_colwidth", None):
display(retrieved_chunks)
| Retrieved Chunks | Reranked Relevance Score | |
|---|---|---|
| 0 | Optimized collaboration modes – Choose between supervisor mode and supervisor with routing mode. With routing mode, the supervisor agent will route simple requests directly to specialized subagents, bypassing full orchestration. For complex queries or when no clear intention is detected, it automatically falls back to the full supervisor mode, where the supervisor agent analyzes, breaks down problems, and coordinates multiple subagents as needed.\n\nIntegrated trace and debug console – Visualize and analyze multi-agent interactions behind the scenes using the integrated trace and debug console.\n\nWhat’s new in general availability?\n\nThe GA release introduces several key enhancements based on customer feedback, making multi-agent collaboration more scalable, flexible, and efficient:\n\nInline agent support – Enables the creation of supervisor agents dynamically at runtime, allowing for more flexible agent management without predefined structures.\n\nAWS CloudFormation and AWS Cloud Development Kit (AWS CDK) support – Enables customers to deploy agent networks as code, enabling scalable, reusable agent templates across AWS accounts. | 0.998379 |
| 1 | Supervisor with routing mode\n\nSimple queries are routed directly to a relevant sub-agent.\n\nComplex or ambiguous requests trigger the supervisor to coordinate multiple agents to complete the task.\n\nWatch the Amazon Bedrock multi-agent collaboration video to learn how to get started.\n\nConclusion\n\nBy enabling seamless multi-agent collaboration, Amazon Bedrock empowers businesses to scale their generative AI applications with greater efficiency, accuracy, and flexibility. As organizations continue to push the boundaries of AI-driven automation, having the right tools to orchestrate complex workflows will be essential. With Amazon Bedrock, companies can confidently build AI systems that don’t just generate responses but drive real impact—automating processes, solving problems, and unlocking new possibilities across industries.\n\nAmazon Bedrock multi-agent collaboration is now generally available.\n\nLearn more: Automate tasks in your application using AI agents\n\nCode samples: Amazon Bedrock agent samples on GitHub\n\nTry it out today in the AWS Management Console for Amazon Bedrock. | 0.966339 |
| 2 | “Agricultural innovation leader Syngenta is using Amazon Bedrock Agents as part of its Cropwise AI solution, which gives growers deep insights to help them optimize crop yields, improve sustainability, and drive profitability. With multi-agent collaboration, Syngenta will be able to use multiple agents to further improve their recommendations to growers, transforming how their end-users make decisions and delivering even greater value to the farming community.”\n\nThis collaboration between Syngenta and AWS exemplifies the transformative potential of generative AI and multi-agent systems in agriculture, driving innovation and supporting sustainable farming practices.\n\nHow multi-agent collaboration works\n\nAmazon Bedrock automates agent collaboration, including task delegation, execution tracking, and data orchestration. Developers can configure their system in one of two collaboration modes:\n\nSupervisor mode\n\nThe supervisor agent receives an input, breaks down complex requests, and assigns tasks to specialized sub-agents.\n\nSub-agents execute tasks in parallel or sequentially, returning responses to the supervisor, which consolidates the results.\n\nSupervisor with routing mode | 0.451430 |
5. Define the Amazon Bedrock model for inference#
Let's select the Amazon Bedrock model the same way we did in the previous labs.
Tip: Please opt for frugal practices when using Amazon Bedrock such as using smaller LLMs for simpler tasks and only reserving the use of the larger LLMs for more complex use cases.
from langchain_aws import ChatBedrockConverse
from langchain_core.output_parsers import StrOutputParser
bedrock_llm = ChatBedrockConverse(
model="amazon.nova-lite-v1:0",
temperature=0,
max_tokens=None,
)
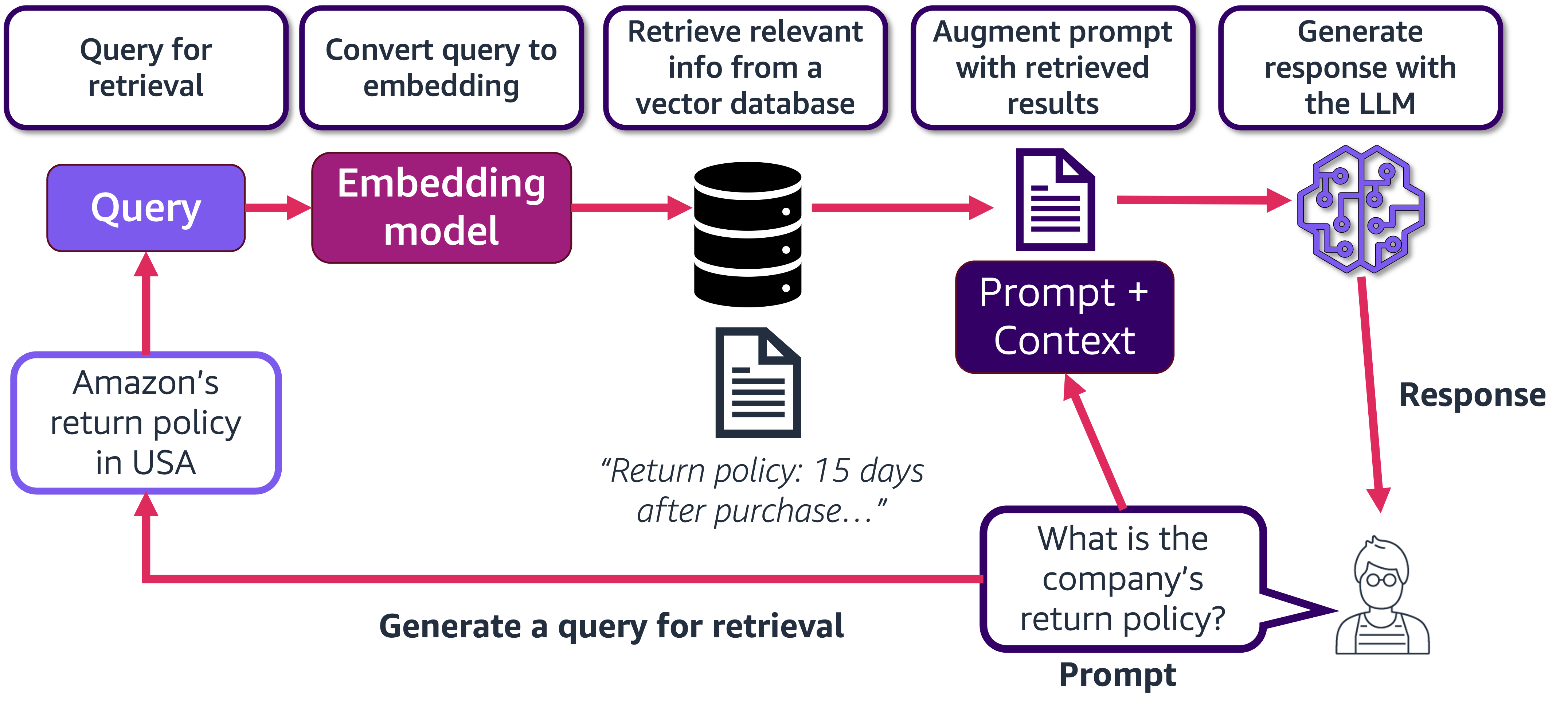
6. Retrieval Q&A#
Let's build a Q&A application with a retriever. The retriever returns the chunks from a document based on the relevance with the query. We will examine how using a retriever improves the quality of response by comparing the RAG solution with the vanilla LLM responses.
from langchain_core.output_parsers import StrOutputParser
from langchain.prompts import PromptTemplate
# Supress warnings
warnings.filterwarnings("ignore")
qa_template = """Use the given context to answer the question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Keep the answer as concise as possible.
Context: {context}
Question: {question}
Answer:
"""
# Define the prompt template for Q&A
qa_prompt_template = PromptTemplate.from_template(qa_template)
# Define the final chain
retrieval_qa_chain = qa_prompt_template | bedrock_llm | StrOutputParser()
query = "How can you use Amazon Bedrock for multi-agent collaboration?"
# First the relevant documents are retrieved and reranked
retrieved_docs = updated_retriever.invoke(query)
docs_content = "\n\n".join(doc.page_content for doc in retrieved_docs)
# Then the chain is invoked with the query and the retrieved data
rag_response = retrieval_qa_chain.invoke(
{
"question": query,
"context": docs_content
}
)
Markdown(rag_response)
Amazon Bedrock simplifies the creation of networks of specialized agents that communicate and coordinate under the guidance of a supervisor agent. It allows developers to distribute workloads across specialized agents, improve execution efficiency by parallelizing tasks, and enhance security and governance by restricting agent access to necessary data.
Activity: Compare RAG vs. vanilla LLM#
Let's compare the retrieval Q&A response against a vanilla LLM response to see how RAG improves the quality and accuracy of answers.
from mlu_utils.widgets.rag_llm_comparison import create_rag_comparison_ui
create_rag_comparison_ui(updated_retriever, bedrock_llm)
7. Quizzes#
Well done on completing the lab! Now, it's time for a brief knowledge assessment.

Challenge: Knowledge Assessment#
Answer the following questions to test your understanding of embeddings, document loaders and RAG workflows.
from mlu_utils.quiz_questions import lab3a_question1, lab3a_question2
lab3a_question1.display()
lab3a_question2.display()
Conclusion#
In this lab, you have:
Learned how to load documents from various sources using LangChain document loaders
Implemented document splitting to break large texts into manageable chunks
Created vector embeddings and stored them in a vector database
Used re-rankers to improve retrieval quality
Built a Retrieval Augmented Generation (RAG) system using LangChain and Amazon Bedrock
Compared RAG responses with vanilla LLM responses to understand the benefits of retrieval
Additional Resources#
LangChain Data Connection Documentation
Amazon Bedrock Documentation